

What is a benchmark test?
It is a test performed to compare and evaluate the processing performance of computers. The nurse scheduling problem is academic, a branch of combinatorial optimization, and various algorithms have been researched and developed since the 1980s.
When presenting a new algorithm, we want to discuss the superiority or inferiority of the algorithm. Still, if all the presenters used different test instances, it is impossible to compare them.
Therefore, various benchmark tests have been published.
In Japan, the benchmark test presented by Dr. Ikegami of Seikei University is widely referred to at international conferences. This benchmark is an instance (an entity that models the evaluation rules of the work schedule) that was modeled by going to actual nursing sites, It is the closest to the actual work situation in Japan and is a critical benchmark test for measuring functional performance.
Benchmark Test Results
We publish results .
It isn’t apparent, so let’s look at some key points.
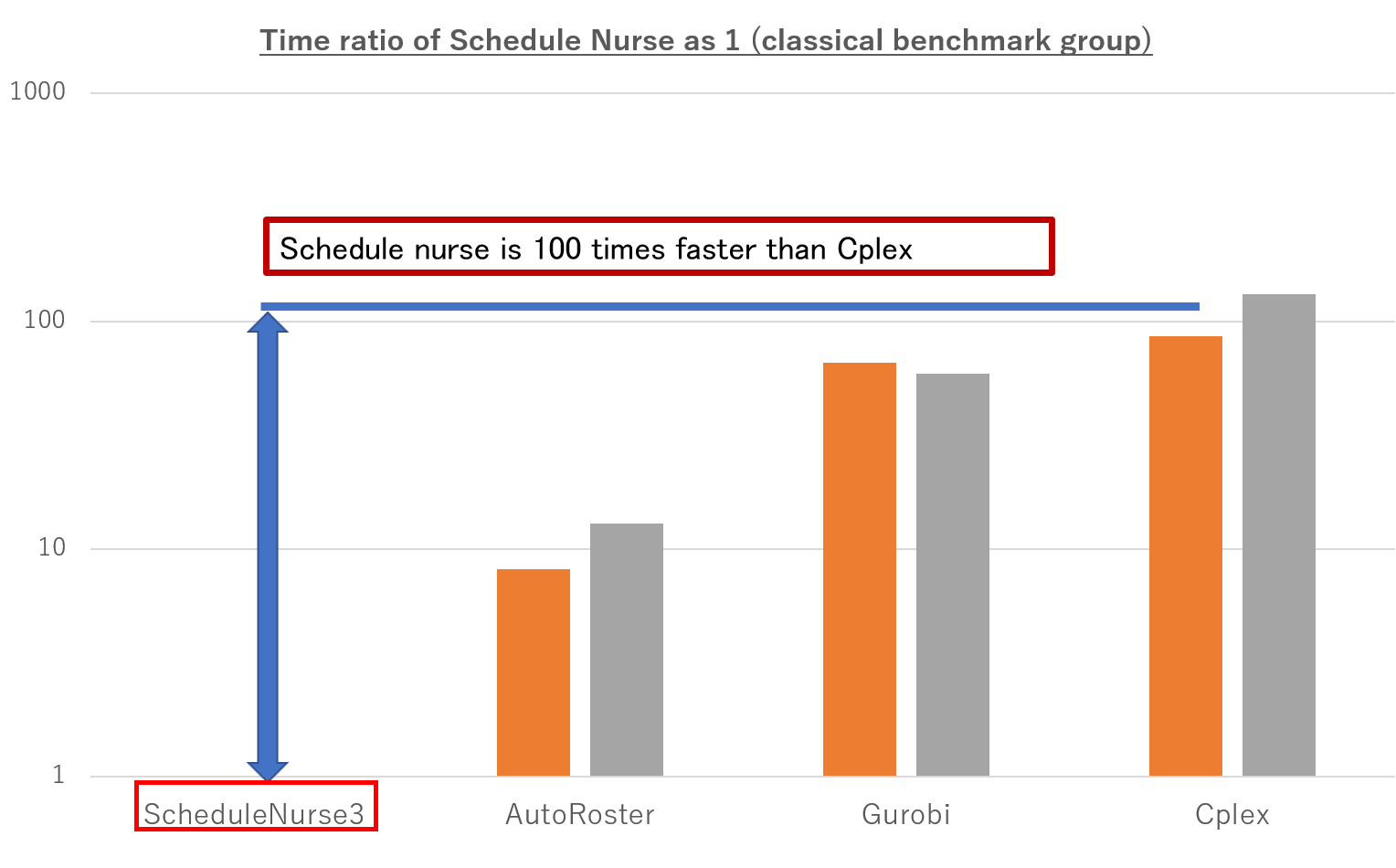
The graph below compares speed to solving for classical benchmark tests.
Auto Roster is a spin-out from the prestigious University of Nottingham in the UK, Gurobi is the world’s best general-purpose MIP solver, and Cplex is IBM.
Optimality Proven is the time ratio to reach the optimal solution, and Optimality Reached is the ratio to get the optimal solution.
For example, let’s look at a specific Dr. Ikegami benchmark. The vertical axis is the change in the objective function value. The objective function value represents the degree of dissatisfaction and is the sum of the error weight multiplied by the number of errors. Ideally, it is zero, but it may not be zero due to physical limitations.
For example, if some of the required daily night shifts could not be assigned or if all of the staff’s desired vacations could not be accommodated, the objective function value would be much larger. However, there is a value at which the objective function value cannot physically be reduced any further, which is called the “optimal value.
The Schedule Nurse reaches the optimal solution in a few seconds and recognizes that it is the optimal solution within 10 seconds. In contrast, Gurobi takes more than 100 seconds, Cplex takes thousands of seconds, and Autoroster has not reached its optimal value.
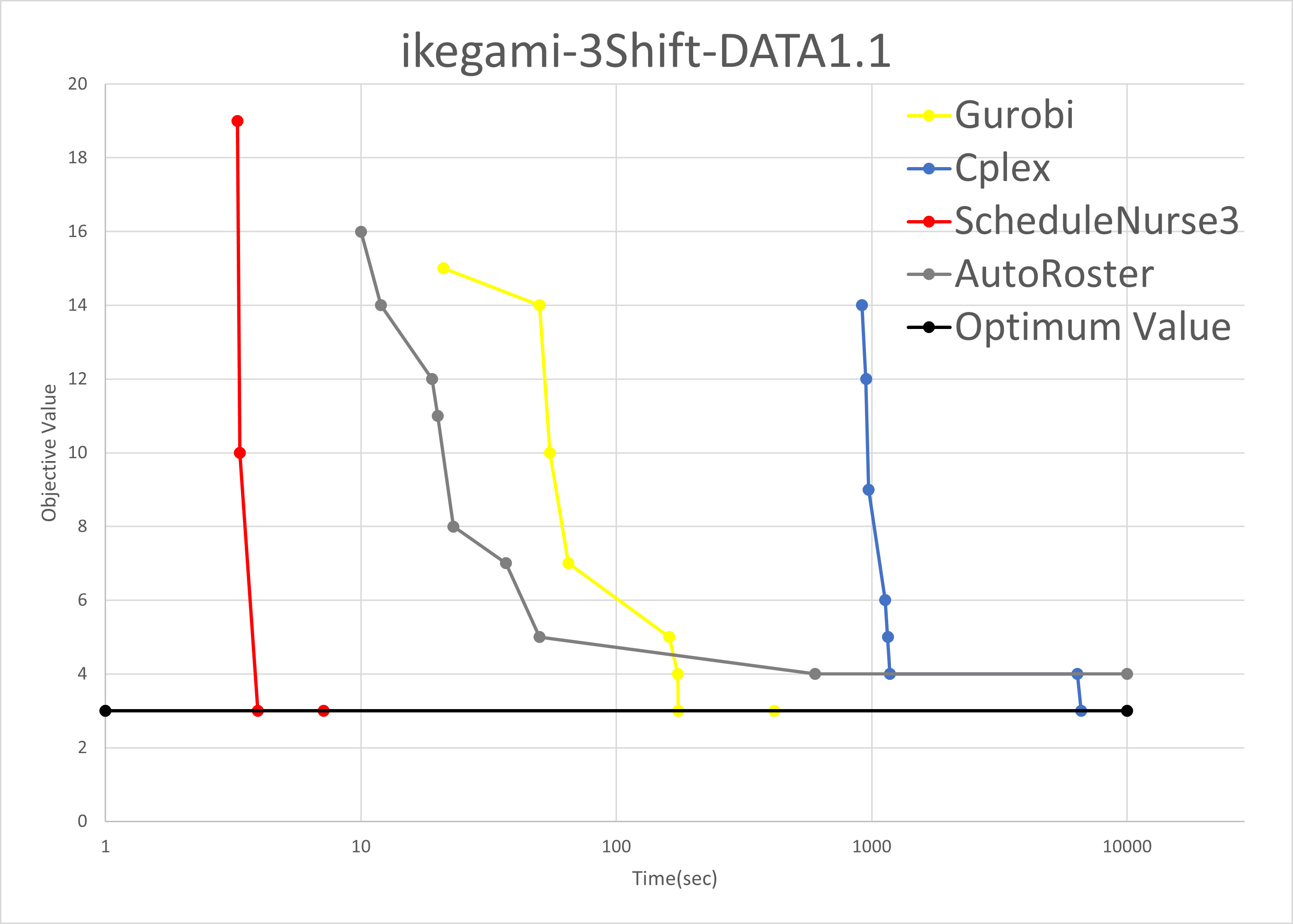
The red line in the figure above, which is a steeply declining red line, is the Schedule Nurse, plotted in the log below. It shows the decrease in the objective function value of the Schedule Nurse.
It takes about 1 second to find a solution that satisfies all hard constraints. Still, at this stage, the objective function value is more than tens of thousands, and many constraints, including staff vacation requests, are still unsatisfied.
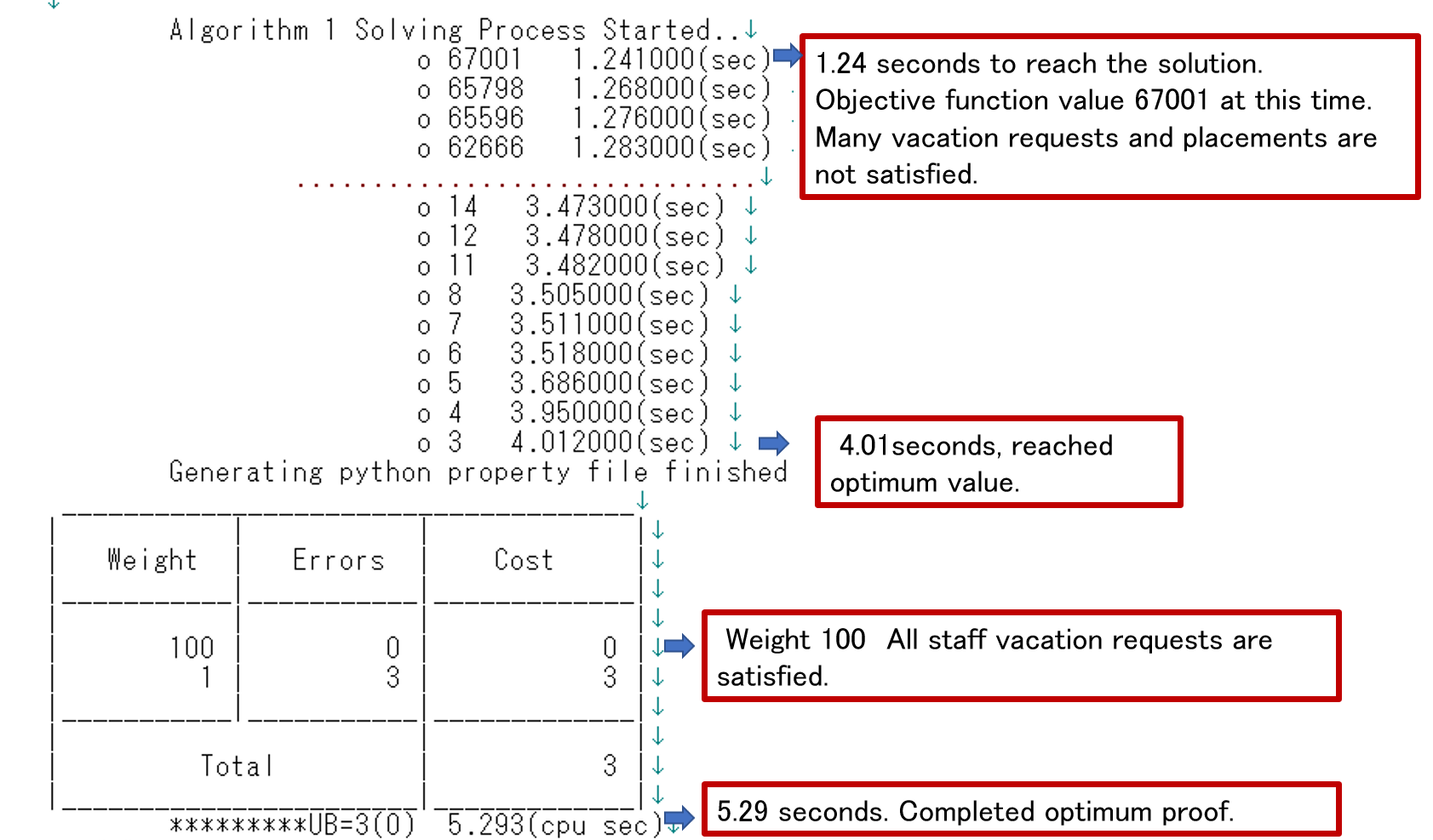
In about 4 seconds, the optimal value is reached, but at this stage, we still do not know if it is the optimal value (later, we will see that it was the optimal value). (Later, we will understand that this was the optimal value.)
After about 5 seconds, the timeout is reached.
In about 5 seconds, the process finishes without waiting for a timeout, indicating that even the optimality proof has been completed.
At this time, the error for weight 100 is 0, which indicates that all of the following staff wishes have been met.
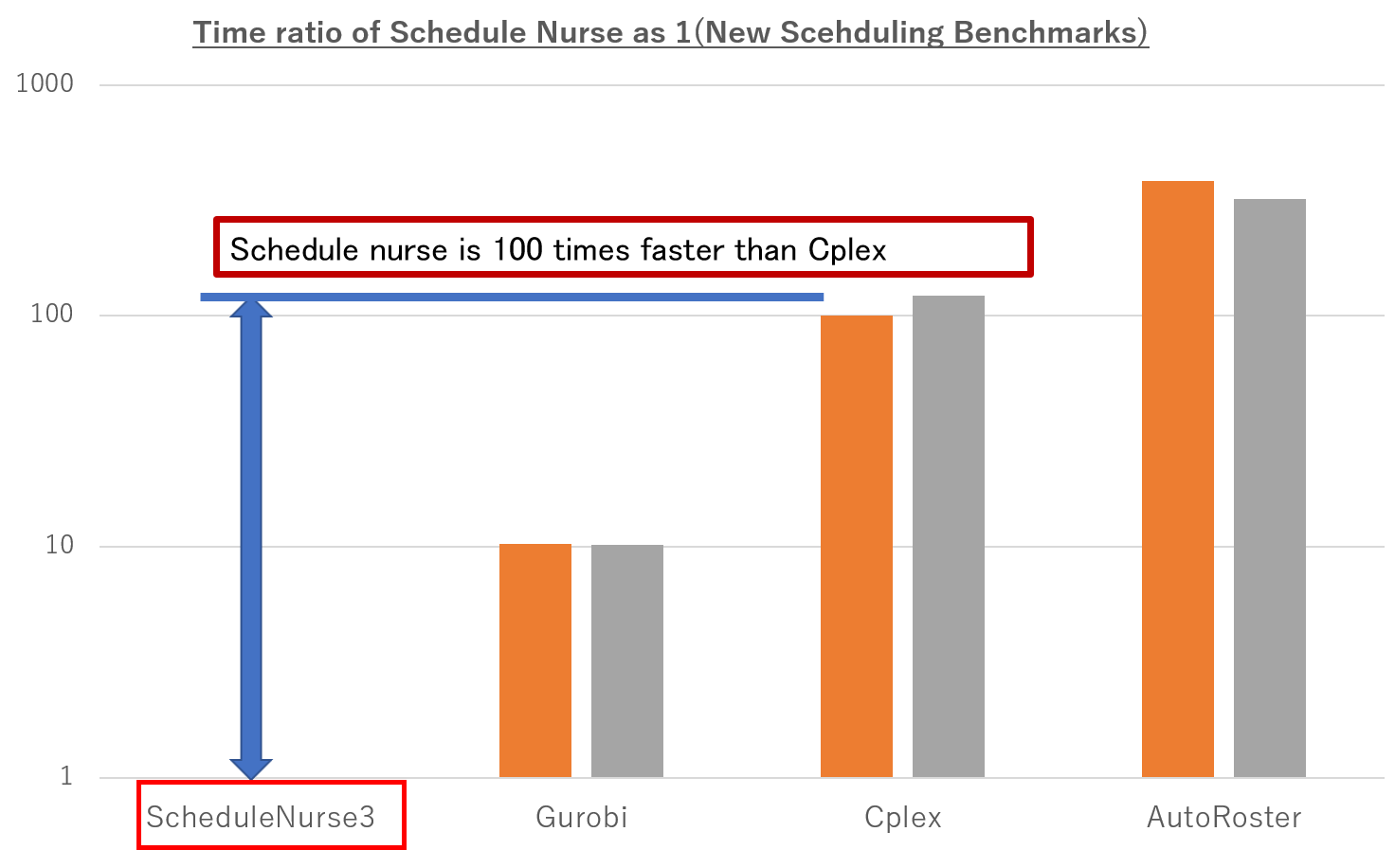
The next graph is from a different set of benchmark tests, New Scheduling Benchmarks.
Optimization solver
The Gurobi results are simply a speed comparison. Still, for example, if we look at Dr. Ikegami’s benchmark at 10 seconds, it means that no software other than ScheduleNurse has solved the problem (no solution exists). One hundred seconds shows many areas where a solution exists in other solvers, but the rest request is not yet satisfied. In a 1000-second Cplex, this means that the required shift is several times short of or over the physical limit,
Note that benchmark results are different from your project. Benchmark results are not everything. The benchmark test is one of many instances, not your project.
It is only a sampled result, so choosing a company with many benchmarks is essential.
As we have seen above,the performance of the optimization solver is directly related to how well it can balance staffing allocations and staff vacation requests. It is directly related to balancing staffing allocation and staff vacation requests.
Even with the world’s most powerful solver, the knowledge giant Gurobi, the scheduling problem for nurses is difficult. And it is probably even harder with commercial work schedule software.
Does your software publish benchmark results?
How can you solve the nurse scheduling problem if you can’t get your staff’s vacation requests in, can’t assign the team to night shifts every day, or can’t satisfy both at the same time?
Don’t worry, we’ve got you covered. All you need to do is to use the optimization capabilities of the Schedule Nurse.
Benchmark Test Types
I think it can be divided into the following four types.
1. Classical Benchmark Test Group
2. New Scheduling Benchmarks
3. Nurse Scheduling Competition I
4. Nurse Scheduling Competition II
Classical Benchmark Test Group
This is a group of classical bench benchmarks, including Dr. Ikegami’s benchmark tests. These are mainly modeled according to the actual situation at the time in each country.
Scheduling Benchmarks
They are divided into 24 scales, like 24 etudes.
| Instance Name | Weeks(A) | Number of Staff(B) | Number of Shifts(C) | =A * 7 * (B+1)*C | Scale |
|---|---|---|---|---|---|
| Instance1 | 2 | 8 | 1 | 224 | 1.0 |
| Instance2 | 2 | 14 | 2 | 588 | 2.6 |
| Instance3 | 2 | 20 | 3 | 1120 | 5.0 |
| Instance4 | 4 | 10 | 2 | 840 | 3.8 |
| Instance5 | 4 | 16 | 2 | 1344 | 6.0 |
| Instance6 | 4 | 18 | 3 | 2016 | 9.0 |
| Instance7 | 4 | 20 | 3 | 2240 | 10.0 |
| Instance8 | 4 | 30 | 4 | 4200 | 18.8 |
| Instance9 | 4 | 36 | 4 | 5040 | 22.5 |
| Instance10 | 4 | 40 | 5 | 6720 | 30.0 |
| Instance11 | 4 | 50 | 6 | 9800 | 43.8 |
| Instance12 | 4 | 60 | 10 | 18480 | 82.5 |
| Instance13 | 4 | 120 | 8 | 30240 | 135.0 |
| Instance14 | 6 | 32 | 4 | 6720 | 30.0 |
| Instance15 | 6 | 45 | 6 | 13230 | 59.1 |
| Instance16 | 8 | 20 | 3 | 4480 | 20.0 |
| Instance17 | 8 | 32 | 4 | 8960 | 40.0 |
| Instance18 | 12 | 22 | 3 | 7392 | 33.0 |
| Instance19 | 12 | 40 | 5 | 20160 | 90.0 |
| Instance20 | 26 | 50 | 6 | 63700 | 284.4 |
| Instance20 | 26 | 50 | 6 | 63700 | 284.4 |
| Instance22 | 52 | 50 | 10 | 200200 | 893.8 |
| Instance22 | 52 | 100 | 16 | 618800 | 2762.5 |
| Instance24 | 52 | 150 | 32 | 1801800 | 8043.8 |
At the time of publication in 2014, only about half of that set of instances had known optimal values. Still, with the development of the MIP solver, as of 2023, only two instances of the problem remain to be solved.
Since then, artificial (mechanically) computer-generated benchmarks have been used.
You can see the record updates at here , where you will find several names of Tak.Sugawara (This article’s author).
Nurse Scheduling Competition I
The first Competition was held in 2010, with Sprint/Medium/Long categories. There are two categories: instances published before the Competition and instances published (hidden) at the time of the Competition.
The primary papers are as follows.
https://www.sciencedirect.com/science/article/pii/S0377221711011362
https://www.researchgate.net/profile/Tulio_Toffolo/publication/264120532_Integer_Programming_Techniques_for_the_Nurse_Rostering _ Problem/links/589ae7a7aca2721f0db15292/Integer-Programming-Techniques-for-the-Nurse-Rostering-Problem.pdf?origin=publication_ detail
This Competition was written before I started working on the NSP. Dr. Nonobe of Hosei University won the third prize. The top is the first-prize winner’s paper. (You have to purchase it to see it.) The second is the well-known team from the University of Nottingham, and the third is Mr. Santos, whose paper was published after the Competition and has also made a significant contribution to COIN Cut Generator. It is also available as a benchmark problem MIPLIB2017 for the MIP solver.
In order of performance, the three solutions are: Hybrid type (MIP solver + meta-solver). Branch & Price type (University of Nottingham). Dr. Nonobe’s meta-solver (Tab Search).
Although the Competition is more than 10 years old, even nowadays, papers on meta-solving methods using these instances have been published.
https://www.sciencedirect.com/science/article/pii/S1319157818300363
This time, I spent more than a month solving all the problems.
As a result, we can present the KnownBest solution for all problems and the exact solution for almost all issues (we have updated some of the LB values reported above).
For the Sprint problem, we can reach the KnownBest solution within 10 seconds and show the exact solution within 10 seconds for almost all problems. All of these are due to Algorithm 4.
There are three types of problems: Sprint, Medium, and Long.
| Types | Test Period | Descriptions |
|---|---|---|
| Sprint | 10 seconds or less | 10 Early, 10 Late, 10 Hidden |
| Medium | 10 minutes or less | Early 5 instances, Late 5 instances, Hidden 5 instances |
| Long | 10 hours or less | Early 5, Late 5, Hidden 5 |
The Early/Late instances were presented before the Competition, while the Hidden instances were presented for the first time at the Competition.
However, it is unclear what kind of problems may occur with Hidden, and there is a possibility that the implementation of the software may be affected.
The University of Nottingham grades show a zero in the Hidden section, as mentioned in Curtois’ paper, which seems to have the above problem.
Nurse Scheduling Competition II
This is the second Competition in 2015. Dynamic instances were used during the Competition, where constraints were presented every week.
But in subsequent research papers, papers that interpret the entire instance as a static constraint have become popular.
In this Competition, the concept of tasks and shifts was added, making it the most difficult problem in terms of size and complexity.
There are many instances where the optimal value is not known even now, as it is believed that the test was aimed at making it impossible for MIP solvers to solve.
Currently, in all instances, all of the Schedule Nurse results are KnownBests (world record). No better results have been reported to the best of the author’s knowledge.